




| Tweet | Follow @co2science |
By Andy May
In my last post I plotted the NASA CO2 and the HadCRUT5 records from 1850 to 2020 and compared them. This was in response to a plot posted on twitter by Robert Rohde implying they correlated well. The two records appear to correlate because the resulting R2 is 0.87. The least square's function used made the global temperature anomaly a function of the logarithm to the base 2 of the CO2 concentration (or 'log2CO2'). This means the temperature change was assumed to be linear with the doubling of the CO2 concentration, a common assumption. The least squares (or 'LS') methodology assumes there is no error in the measurements of the CO2 concentration and all error resulting from the correlation (the residuals) resides in the HadCRUT5 global average surface temperature estimates.
In the comments to the previous post, it became clear that some readers understood the computed R2 (often called the coefficient of determination), from LS, was artificially inflated because both X (log2CO2) and Y (HadCRUT5) were autocorrelated and increased with time. But a few did not understand this vital point. As most investors, engineers, and geoscientists know, two time series that are both autocorrelated and increase with time will almost always have an inflated R2. This is one type of "spurious correlation." In other words, the high R2 does not necessarily mean the variables are related to one another. Autocorrelation is a big deal in time series analysis and in climate science, but too frequently ignored. To judge any correlation between CO2 and HadCRUT5 we must look for autocorrelation effects. The most tool used is the Durbin-Watson statistic.
The Durbin-Watson statistic tests the null hypothesis that the residuals from a LS regression are not autocorrelated against the alternative that they are. The statistic is a number between 0 and 4, a value of 2 indicates non-autocorrelation and a value < 2 suggests positive autocorrelation and a value >2 suggests negative autocorrelation. Since the computation of R2 assumes that each observation is independent of the others, we hope that we get a value of 2, that way the R2 is valid. If the regression residuals are autocorrelated and not randomthat is normally distributed about the meanthe R2 is invalid and too high. In the statistical program R, this is doneusing a linear fitwith only one statement, as shown below:

This R program reads in the HadCRUT5 anomalies and the log2CO2 values from 1850-2020 plotted in Figure 1, then loads the R library that contains the durbinWatsonTest function and runs the function. I only supply the function with one argument, the output from the R linear regression function lm. In this case we ask lm to compute a linear fit of HadCRUT5, as a function of log2CO2. The Durbin-Watson (DW) function reads the lm output and computes the DW statistic of 0.8 from the residuals of the linear fit by comparing them to themselves with a lag of one year.
The DW statistic is significantly less than 2 suggesting positive autocorrelation. The p value is zero, which means the null hypothesis that the HadCRUT5-log2CO2 linear fit residuals are not autocorrelated is false. That is, they are likely autocorrelated. R makes it easy to do the calculation, but it is unsatisfying since we don't get much understanding from running it or from the output. So, let's do the same calculation with Excel and go through all the gory details.
The Gory Details
The basic data used is shown in Figure 1, it is the same as Figure 2 in the previous post.

Strictly speaking, autocorrelation refers to how a time series correlates with itself with a time lag. Visually we can see that both curves in Figure 1 are autocorrelated, like most times series. What this means is that a large part of each value is determined by its preceding value. Thus, the log2CO2 value in 1980 is very dependent upon the value in 1979, and this is also true of the 1980 and 1979 values of HadCRUT5. This a critical point since all LS fits assume that the observations used are independent and that the residuals between the observations and the predicted values are random and normally distributed. R2 is not valid if the observations are not independent, a lack of independence will be visible in the regression residuals. Below is a table of autocorrelation coefficients for the curves in Figure 1 for time lags of one to eight years.

The autocorrelation values in Table 1 are computed with the Excel formula found here. The autocorrelation coefficients shown, like conventional correlation coefficients, vary from -1 (negative correlation) to +1 (positive correlation). As you can see in the Table both HadCRUT5 and log2CO2 are strongly positively autocorrelated, that is they are monotonically increasing, as we can confirm with a glance at Figure 1. The autocorrelation decreases with increasing lag, which is normally the case. All that means is that this year's average temperature is more closely related to last year's temperature than the year before and so on.
Row number one of Table 1 tells us that about 76% of each HadCRUT5 temperature and over 90% of each NASA CO2 concentration are dependent upon the previous year's value. Thus, in both cases, each yearly value is not independent.
While the numbers given above apply to the individual curves in Figure 1, autocorrelation can clearly affect the regression statistics when the temperature and CO2 curves are regressed against one another. This bivariate autocorrelation is usually examined using the Durbin-Watson statistic mentioned above, and named for James Durbin and Geoffrey Watson.
Linear fit
As I did in the R program above, traditionally the Durbin-Watson calculation is performed on a linear regression of the two variables of interest. Figure 2 is like Figure 1, but we have fit LS lines to both HadCRUT5 and Log2CO2.

In Figure 2, orange is log2CO2 and blue is HadCRUT5. The residuals are shown in Figure 3, notice they are not random and appear to autocorrelate as we would expect from the statistics given in Table 1. They are autocorrelated and have the same shape, which is worrying.

The next step in the DW process is to derive a LS fit to the residuals shown in Figure 3, this is done in Figure 4.

Just as we feared, the residuals correlate and have a positive slope. Doing the DW calculations in this fashion, we get a DW statistic of 0.84, close to the value computed in R, but not exactly the same. I suspect that this is because the multiple sum-of-squares computations over 170 years of data leads to the subtle difference of 0.04. We can confirm this by performing the R calculation using the Excel residuals:

This confirms that both calculations match, but there were differences in the sum-of-squares calculations due to the different computer floating-point precision used in Excel and R. So, with a linear fit to both HadCRUT5 and log2CO2, there are serious autocorrelation problems. But both are concave upwards patterns, what if we used an LS fit that is more appropriate than a line? The plots look like a second order polynomial, let's try that.
Polynomial Fit
Figure 5 shows the same data as in Figure 1, but we have fit 2nd order polynomials to each of the curves. The CO2 and HadCRUT5 data curve upward, so this is a big improvement over the linear fits above.

I should mention that I did not use the equations on the plot for the calculations, I did a separate fit to decades. The decades were calculated using 1850 as zero and 1850 to 1860 as decimal decades and so on to 2020 so that the X variable in the calculation had smaller values in the sum of squares calculations. This is to get around the Excel computer floating-point precision problem already mentioned.
The next step in the process is to subtract the predicted or trend value for each year from the actual value to create residuals. This is done for both curves, the residuals are plotted in Figure 6.
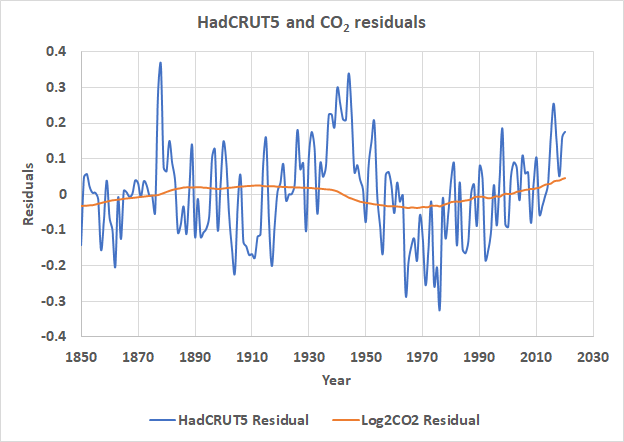
Figure 6 shows us that the residuals of the polynomial fits to HadCRUT5 and log2CO2 still have structure and the structure visually correlates, not a good sign. This is the portion of the correlation left, after the 2nd order fit is removed. In Figure 7 I fit a linear trend to the residuals. The R2 is less than in Figure 4

There is still a signal in the data. It is positive, suggesting that if the autocorrelation were truly removed with the 2nd order fit (we cannot say that statistically, but "what if"), there is still a small positive change in temperature, as CO2 increases. Remember, autocorrelation doesn't say there is no correlation, it just invalidates the correlation statistics. If temperature is mostly dependent upon the previous year's temperature, and we can successfully remove that influence, what remains is the real dependency of temperature on CO2. Unfortunately, we can never be sure we removed the autocorrelation and can only speculate that Figure 7 may be the true dependency between temperature and CO2.
The Durbin-Watson statistic
Now the calculations to compute the Durbin-Watson joint autocorrelation are done, but this time we used a 2nd order polynomial regression. Below is a table showing the Durbin-Watson statistic between HadCRUT5 and log2CO2 for a lag of one year. The calculations were done using the procedure described here.

The Durbin-Watson value of 0.9, for a one-year lag, confirms what we saw visually in Figures 5 and 6. The residuals are still autocorrelated, even after removing the second order trend. The remaining correlation is positive, as we would expect, presumably meaning that CO2 has some small influence on temperature. We can confirm this calculation in R:

Discussion
The R2 that results from a LS fit of CO2 concentration and global average temperatures is artificially inflated because both CO2 and temperature are autocorrelated time series that increase with time. Thus, in this case, R2 is an inappropriate statistic. R2 assumes that each observation is independent and we find that 76% of each year's average global temperature is determined by the previous year's temperature, leaving little to be influenced by CO2. Further, 90% of each year's CO2 measurement is determined by the previous year's value.
I concluded that the best function for removing the autocorrelation was a 2nd order polynomial, but even when this trend is removed, the residuals are still autocorrelated and the null hypothesis that they were not had to be rejected. It is disappointing that Robert Rohde, a PhD, would send out a plot of a correlation of CO2 and global average temperature implying that the correlation between them was meaningful without further explanation (as we showed in Figure 1 of the previous post) but he did.
Jamal Munshi did a similar analysis to ours in a paper in 2018 (Munshi, 2018). He notes that the consensus idea that increasing emissions of CO2 cause warming, and that the warming is linear with the doubling of CO2 (Log base 2) is a testable hypothesis. This hypothesis has not tested well because the uncertainty in the estimate of the warming due to CO2 (climate sensitivity) has remained stubbornly large for over forty years, basically ±50%. This has caused the consensus to try and move away from climate sensitivity toward comparisons of warming to aggregate carbon dioxide emissions, thinking they can get a narrower and more valid correlation with warming. Munshi continues:
"This state of affairs in climate sensitivity research is likely the result of insufficient statistical rigor in the research methodologies applied. This work demonstrates spurious proportionalities in time series data that may yield climate sensitivities that have no interpretation. [Munshi's] results imply that the large number of climate sensitivities reported in the literature are likely to be mostly spurious. Sufficient statistical discipline is likely to settle the climate sensitivity issue one way or the other, either to determine its hitherto elusive value or to demonstrate that the assumed relationships do not exist in the data."
(Munshi, 2018)
While we used CO2 concentration in this post, many in the "consensus" are now using total fossil fuel emissions in their work, thinking that it is a more statistically valid quantity to compare to temperature. It isn't, the problems remain, and in some ways are worse, as explained by Munshi in a separate paper (Munshi, 2018b). I agree with Munshi that statistical rigor is sorely lacking in the climate community. The community all too often use statistics to obscure their lack of data and statistical significance, rather than to inform.
The R code and Excel spreadsheet used to perform all the calculations in this post can be downloaded here.
Works Cited
Munshi, J. (2018). The Charney Sensitivity of Homicides to Atmospheric CO2: A Parody. SSRN. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3162520
Munshi, J. (2018b). From Equilibrium Climate Sensitivity to Carbon Climate Response. SSRN. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3142525
Posted 16 November 2021